

Agentic testing is not a nicer wrapper around manual QA. It changes the unit of work from “write this test case” to “understand this product behavior, challenge it, and keep validating it as the system changes.”
That’s the point most executives miss. Manual test writing doesn’t fail because testers are lazy or engineers don’t care. It fails because modern software changes faster than humans can maintain exhaustive scripts across product, data, integrations, permissions, AI behavior, and UI states.
I’ve spent more than 20 years leading engineering organizations, and my belief has hardened: testing accountability belongs with the developer. The problem is that, historically, we didn’t have a practical operating model to make that true. Agentic testing finally makes shift-left accountability operational instead of aspirational.
Manual Test Writing Is a Bad Abstraction
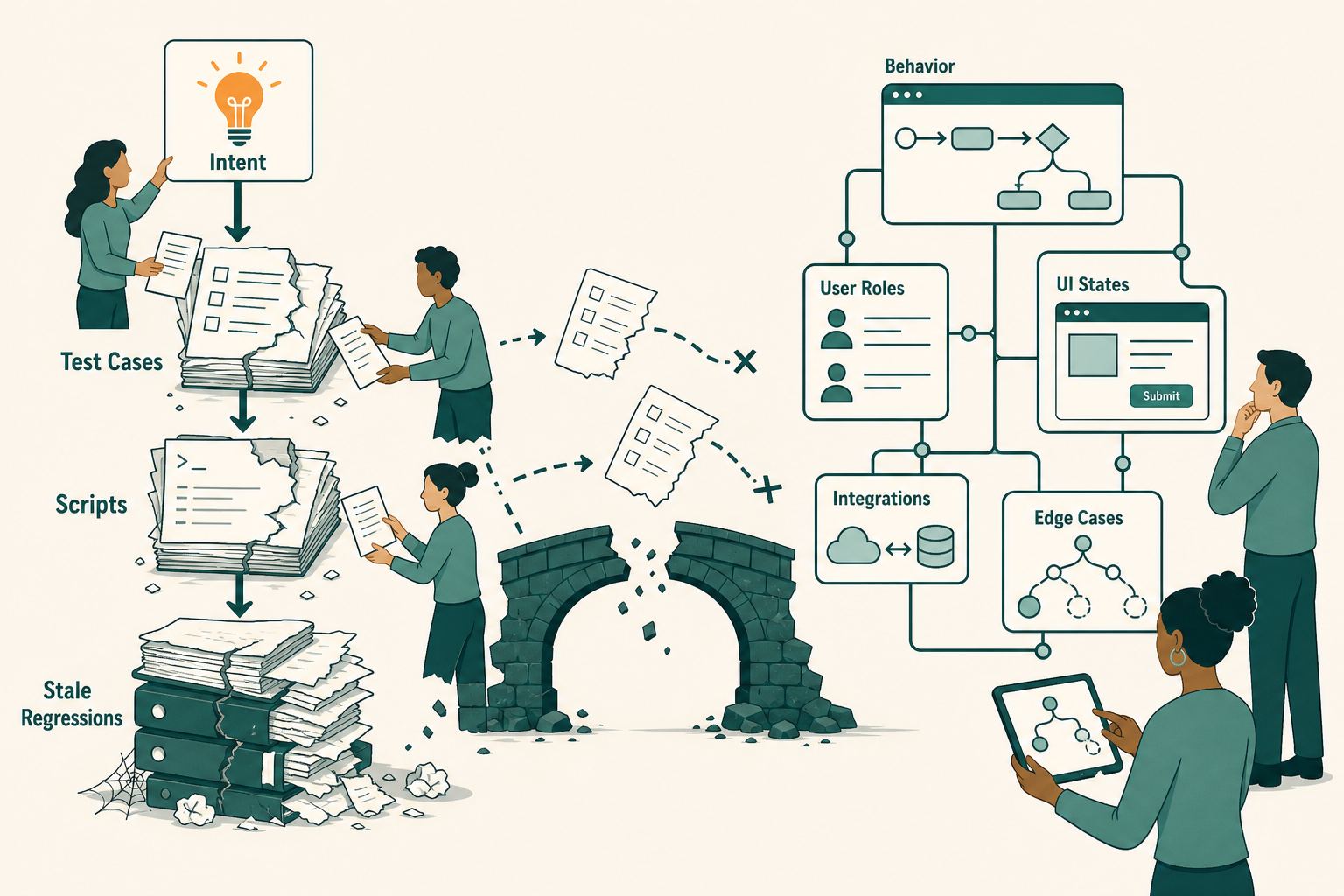
The problem with manual test writing is not effort. It’s abstraction.
A human converts product intent into a test case. Another human converts that test case into a script, often in Playwright, Cypress, Selenium, Appium, Postman, or a homegrown framework. Then the product changes, and the test becomes stale, noisy, incomplete, or politically untouchable because “it protects production.”
That workflow made sense when software shipped in slower cycles and most behavior lived inside predictable screens. It makes less sense when a release includes UI changes, API behavior, feature flags, permission models, LLM calls, payment edge cases, data migrations, and third-party dependency shifts.
Manual tests usually describe the path the team already expects. That’s useful, but limited.
The damaging bugs are often in the interactions nobody wrote down: a stale entitlement, a missing empty state, an unexpected retry, an old mobile viewport, a user role that nobody in product remembered existed.
A good QA engineer can find those issues. The constraint is that we ask them to spend too much time writing and maintaining artifacts instead of interrogating the system.
Manual test writing creates a false sense of completeness. A long spreadsheet looks serious. A giant regression suite looks disciplined. A green CI pipeline looks like control.
None of that proves the product behaves correctly for the user. It also lets engineering pretend quality is downstream, which is the operating failure underneath the testing failure.
Agentic QA Changes the Work From Scripts to Investigation
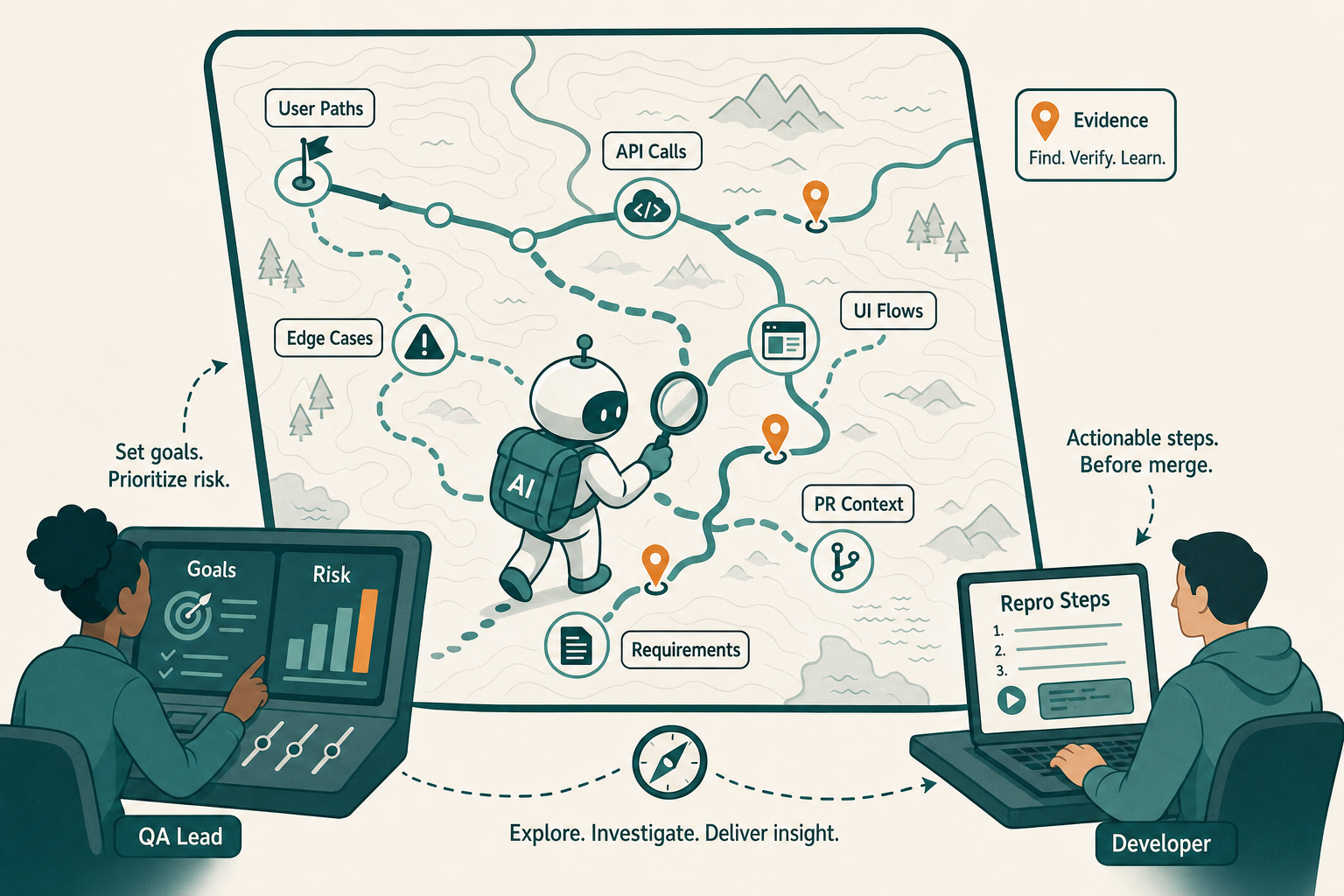
Agentic QA is stronger because the agent can reason over intent, state, and change instead of only executing prewritten instructions.
The agent doesn’t replace testing judgment. It absorbs the mechanical work that steals time from judgment. It can read product requirements, inspect UI flows, compare behavior across builds, generate test ideas, run them, summarize failures, and propose reproducible cases.
That’s a different operating model.
The human is no longer the person typing every assertion. The human sets goals, defines risk, reviews evidence, and decides what matters. The developer remains accountable for whether the change is shippable.
This is where shift-left becomes real. A developer supported by a QA agent can validate intent before merge, not wait for a separate QA gate to discover obvious problems days later. The agent strengthens developer accountability instead of excusing it.
This is why agentic testing belongs in the same strategic category as agentic coding. I wrote about that broader shift in Why Agentic Coding Is Different This Time. The pattern is identical: the value moves from production of artifacts to supervision of autonomous work.
What the agent can do better than a script-first process
A test script is narrow by design. It does exactly what it was told to do, which is both its strength and its weakness.
An agent can operate across a wider surface:
- Read a Jira ticket, pull request, or product note and infer behaviors that need validation.
- Navigate a web application like a user, not just call selectors in a fixed sequence.
- Generate multiple paths through the same feature, including unhappy paths and boundary conditions.
- Compare expected product intent against observed behavior.
- Identify when a failure is likely a product defect, environment issue, flaky selector, or test-data problem.
- Produce a human-readable reproduction path for an engineer.
- Suggest missing coverage after observing what changed in the code or interface.
None of this removes the need for deterministic automated tests. You still want stable checks for core flows. You still want contract tests, unit tests, integration tests, and smoke tests.
But those are not enough. They’re the guardrails. Agentic QA is the scout.
The Old QA Pyramid Was Built for a Simpler World
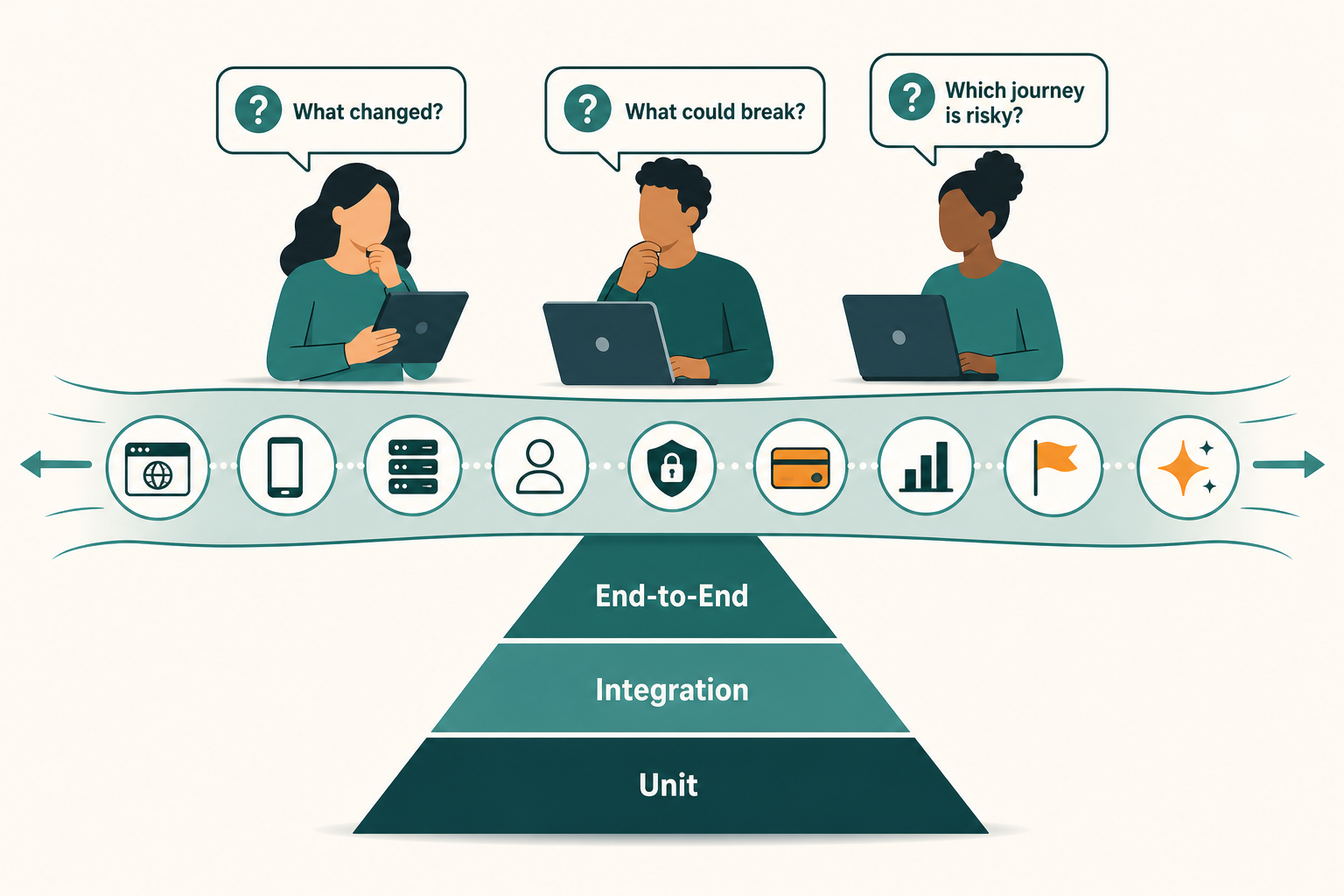
The traditional test pyramid is still useful, but it’s no longer sufficient as the mental model for quality.
The classic advice is sensible: many unit tests, fewer integration tests, even fewer end-to-end tests. It pushed teams away from slow, brittle UI automation and toward faster feedback. That was a good correction.
But the modern product stack has become more behaviorally complex.
A meaningful user experience may involve React or Vue in the browser, a mobile client, backend services, an identity provider, a permissions layer, Stripe, Salesforce, HubSpot, Snowflake, feature flags, analytics events, and AI components that don’t behave like traditional deterministic functions.
The pyramid doesn’t fully capture that.
A unit test can prove a function behaves. It can’t prove the user can complete the job. An integration test can prove systems talk. It can’t prove the experience is coherent.
An end-to-end test can validate one happy path. It can’t explore the messy combinatorics of real usage.
Agentic testing extends the model by adding exploratory automation that operates above and across the pyramid. It can ask, “What changed?” and “What could this break?” and “Which user journey is now risky?”
That’s the work good senior QA people already do, only with more reach and less mechanical drag.
Where deterministic tests still win
Don’t turn this into religion. Deterministic tests are excellent where the behavior is stable, narrow, and important.
Use conventional automated tests for:
- Core business logic with clear inputs and outputs.
- API contracts that downstream systems depend on.
- Security-sensitive permission checks.
- Migration logic where regression impact is high.
- Payment, billing, and entitlement paths.
- Smoke tests that decide whether a build is even worth deeper investigation.
- Known production defects that must never return.
Agentic QA doesn’t replace this. It makes the quality system less blind around it.
The mistake is asking script-based testing to do the whole job. It can’t. It never really could, but the cost was easier to hide when products moved slower.
Manual Test Writing Creates Organizational Debt
Every manual test case becomes a small debt instrument unless someone keeps paying interest on it.
That interest shows up as review meetings, stale screenshots, broken selectors, ambiguous expected results, duplicated coverage, and long regression cycles nobody trusts. QA becomes a bottleneck not because people lack skill, but because the process forces smart people into clerical work.
I’ve seen teams with impressive-looking test inventories where nobody can answer basic executive questions.
What risk does this suite reduce? Which critical customer journeys are weakly covered? Which failures are real? Which tests are obsolete?
If the answer requires archaeology, the system is broken.
Agentic testing doesn’t magically solve governance. It gives governance better raw material. A good agentic QA loop can produce structured evidence: what was explored, what changed, what failed, what was skipped, what looks risky, and what needs human review.
That matters at board level and operating level.
Executives don’t need screenshots of every passed step. They need confidence that quality work is aligned with product risk. Engineering leaders need a faster way to turn change into validation without expanding ceremony.
The real cost is delayed feedback
The most expensive bug is not always the one that reaches production. Often, it’s the one discovered late enough to distort the release.
Late QA feedback creates ugly choices. Delay the release. Patch around the issue. Cut scope. Override the test.
Then engineering gets dragged back into context after it has moved on. That’s where trust decays.
Agentic QA pulls more investigation forward. The earlier an agent can read a change, exercise the product, and point humans toward suspicious behavior, the less drama the organization carries into release decisions.
Speed isn’t the point by itself. Better timing is the point. Accountability is the bigger point.
What Good Agentic Testing Looks Like in Practice
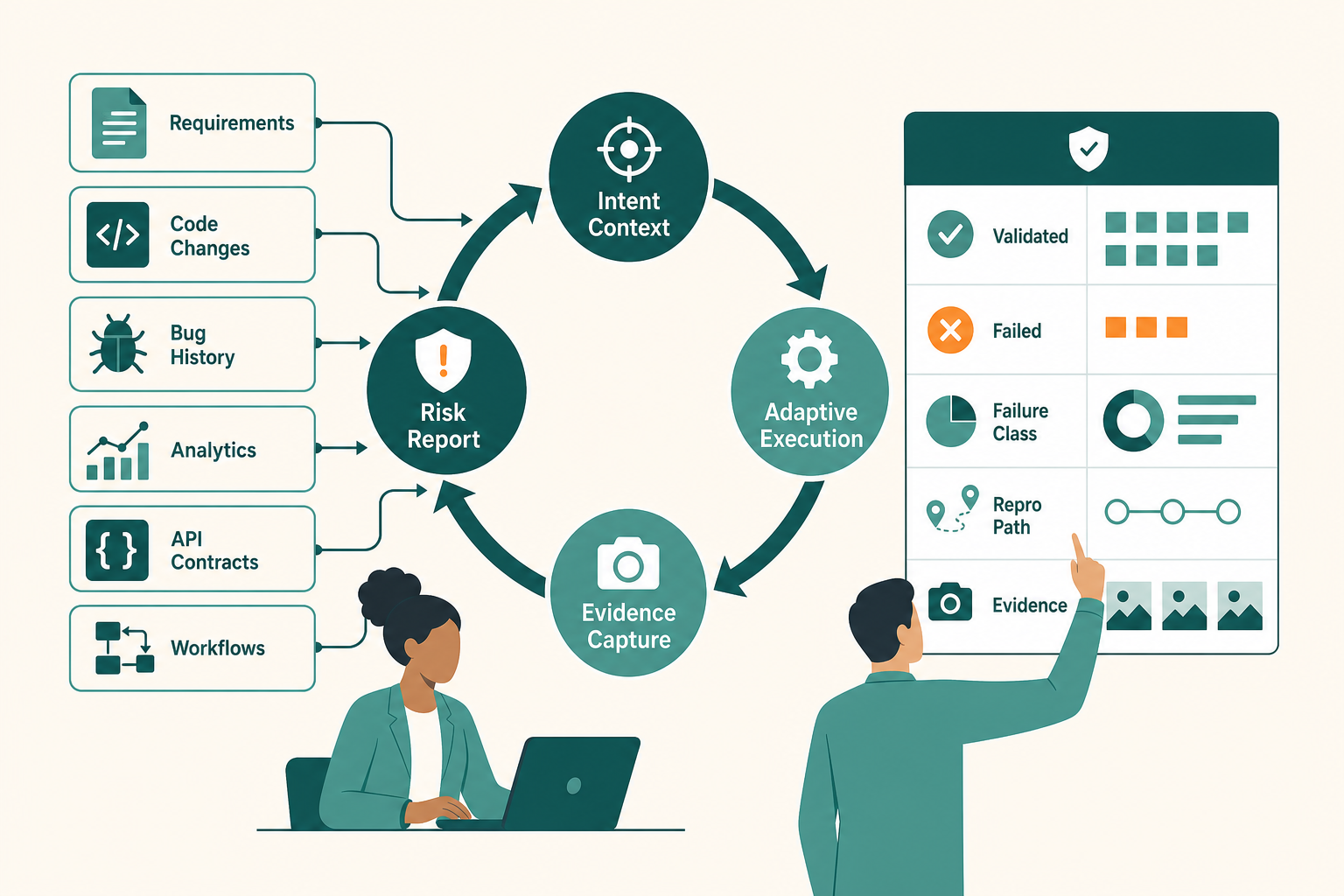
A serious agentic QA system is not a chatbot attached to a browser. It’s an operating loop.
The loop starts with intent. Product requirements, acceptance criteria, historical bugs, analytics signals, code changes, API contracts, and known customer workflows become context. The agent uses that context to plan validation, not just click randomly.
Then it executes. It navigates, calls APIs, checks data state, records evidence, and adapts when the path changes. If the sign-up button moved, it doesn’t collapse like a brittle selector chain.
If the response changed, it investigates whether that change is expected.
Then it reports. Not with a wall of logs, but with a risk summary that a human can act on.
A good report separates signal from noise:
- What behavior was validated.
- What behavior failed.
- Why the failure likely matters.
- How to reproduce it.
- What evidence supports the claim.
- Which related areas may deserve review.
- Whether the issue appears tied to data, environment, permissions, UI, API, or product logic.
That last part is critical. QA that only says “failed” is cheap. QA that explains the likely failure class is valuable.
The QA role gets more senior, not smaller
The best QA people don’t disappear in this model. They become more important.
The QA lead or senior QA engineer defines the testing strategy, tunes the QA agent, and owns the quality system’s evaluation criteria. They decide what “good” looks like for the product domain. They define risk taxonomies, feedback loops, review thresholds, and the QA skills the agent needs to apply.
That doesn’t make them a downstream gatekeeper. It makes them the architect of the testing operating system.
Engineering changes with it. Developers get sharper feedback before merge, not vague bug tickets days later. They’re supported by a QA agent, but they’re not relieved of accountability.
That distinction matters. Agentic QA makes full developer accountability possible because the developer has real-time testing support inside the development flow. QA defines and improves the system that makes that accountability credible.
This is not about reducing QA to a prompt. It’s about moving QA up the value chain and moving responsibility for quality closer to the code.
Why Investors Should Care
Quality systems are operating leverage, and agentic testing changes the leverage profile of software teams.
For PE and VC partners, the question isn’t whether a portfolio company has QA. Most do. The question is whether the QA model can keep pace with product and engineering ambition.
Manual test writing scales poorly in companies with active roadmaps. Add more features, and you add more regression surface. Add more customers, and you add more permissions, configurations, integrations, and edge cases.
Add more engineers, and you add more change throughput.
The old response was more process and more headcount. That can work for a while, but it hardens into drag if the underlying model doesn’t change.
Agentic QA attacks the feedback bottleneck directly. It lets a leaner team interrogate more product behavior, sooner, with a stronger evidence trail. That can influence release confidence, engineering productivity, customer experience, and the credibility of the roadmap.
This matters in diligence too.
A company with thousands of brittle tests and slow releases may look mature from the outside. A company with fewer artifacts but a strong agentic validation loop may be more adaptable. The artifact count is not the asset. The learning rate is the asset.
Ask better questions:
- How does the team decide what to test after a product change?
- Is the developer accountable for validating the change before merge?
- How quickly can it validate a risky workflow?
- How much test maintenance blocks new work?
- Which tests are trusted, and which are ignored?
- Can QA explain release risk in product language?
- Are failures triaged intelligently, or thrown over the wall?
- Does the system learn from production defects?
Those questions reveal the real maturity of the engineering organization.
The Hard Parts Nobody Should Ignore
Agentic testing is powerful, but only if leaders treat it as engineering infrastructure, not a novelty tool.
There are real constraints. Agents need context. They need access to stable environments and safe test data.
They need boundaries around destructive actions. They need observability, screenshots, traces, logs, and clean reproduction paths.
They also need evaluation.
If an agent reports nonsense, people stop trusting it. If it creates noisy tickets, engineers route around it. If it can’t distinguish a real defect from a fixture problem, it becomes another flaky test suite with better prose.
That’s where QA leadership matters. The QA lead owns the testing strategy, tunes the agent, defines acceptance criteria for findings, and tightens the feedback loops between production defects, developer behavior, and agent performance.
The answer is not to wait for perfection. The answer is to implement the loop with discipline.
Start with high-value workflows. Give the agent clear product intent and known constraints. Use it to augment existing Playwright, Cypress, API, and CI practices.
Review its findings like you’d review a junior engineer’s work, then tighten the system as it proves itself.
The first win is usually not full autonomy. It’s better discovery, faster triage, and less human time wasted on repetitive validation. That’s enough to change the economics of QA.
The Agentic-Native Company
The agentic-native company doesn’t treat QA as a downstream checkpoint. It treats quality as a continuous reasoning system embedded in how software is built. Every meaningful change creates a validation conversation: what intent changed, what behavior is now risky, what evidence do we have, and what still needs human judgment.
This is also the moment where testing accountability can finally move where it belongs: to the developer making the change. The QA lead or QA engineer doesn’t become less accountable. They become accountable for the QA strategy, the QA agent, the skills it applies, the evaluation criteria it’s judged against, and the feedback loops that keep it improving. That operating model supports developers instead of excusing them behind a downstream gate.
After 20+ years in engineering leadership, I don’t see agentic QA as a tooling upgrade. I see it as a management upgrade. The best teams won’t be the ones with the biggest test inventories. They’ll be the ones whose systems learn fastest, surface risk earliest, and make shift-left quality accountability real. That’s why agentic testing beats manual test writing.
