


Most people think they've tried agentic AI. They haven't.
What most people have tried is AI-assisted work: a chatbot that answers questions, an autocomplete that suggests the next line of code, a summarizer that condenses a document. Those tools react to what you ask, moment by moment. Useful. But they don't take ownership of anything.
An agent is different. You give it a goal, not a prompt. It decides what steps to take, executes them, evaluates results, adjusts course, keeps going until it thinks the job is done. No waiting for your next instruction.
I started with agentic coding. I gave an agent a real engineering problem, a production system with real infrastructure and real constraints, and let it run end to end. In about 48 hours I reached a point that would normally take weeks. I wrote about that experience in my first article on agentic coding (read it here).
Then I went further. I deployed OpenClaw, an open-source autonomous AI agent platform, and gave it access to my email, calendar, financial accounts, and files. Not as an experiment. As how I actually work.
Six specialized agents running 24/7.
Both experiences taught me the same lesson. The power of agents is real. But so is the danger. The difference between an agent that creates value and one that creates chaos comes down to one thing: configuration.

The Hallucination Problem: When Confidence Becomes the Threat
Agents don't fail the way most people expect. They don't crash. They don't say "I don't know."
They fail politely. With confidence. With plausible explanations and results that look right until you check.
In code, this meant functions that compiled but didn't work. I'd ask the agent to fix the issue. It would try a different approach. That would fail too.
I'd ask again, and the agent would circle back to the original broken solution as if the failure had never happened. Each response sounded authoritative. The results stayed wrong.
In my OpenClaw setup, the same pattern showed up in ways that were harder to catch. An email filed in the wrong folder. Not flagged, not errored, just quietly misplaced. A calendar entry created for a date I didn't ask for. A financial transaction categorized under the wrong budget line.
The agent confirmed each action as completed. It believed it had done the right thing. It hadn't.
The difference is consequence. Wrong code fails visibly. A test breaks, a deployment crashes, a reviewer catches it.
Wrong operations fail silently. A misfiled email sits unnoticed until the deadline it contained has passed. A miscategorized transaction compounds into a reporting error that surfaces weeks later. A calendar mistake costs you a meeting you can't get back.
This is the core danger of agentic AI. Agents are built to keep going. If they aren't explicitly told when to stop, when to verify, when to ask for help, they fill in the gaps on their own. Confidently.
The Frustration Phase: Why Most People Quit
This is where adoption dies.
Instead of accelerating, the work slows down. Every output has to be watched. Every action verified. The agent isn't saving you time. It's creating a new kind of supervision work that didn't exist before.
I found myself auditing everything. Reading every code change line by line, catching subtle errors.
Checking what the agent had done overnight: were emails filed correctly? Did calendar entries match what I asked for? Did financial categorizations make sense?
The question becomes obvious: why not just do it myself?
The tools weren't useless. They were close. But "almost right" is often worse than wrong when you're trying to move fast. The mental overhead of constant verification erases the productivity gain. The promise of autonomy turns into the reality of babysitting.
I nearly quit twice. Not because the technology lacked power. Because the frustration outweighed the benefit.
That's the real adoption problem. Not what agents can do, but whether people can live with them on a daily basis and trust that tomorrow will be better than today.
The Breakthrough
The turning point came when I stopped expecting the agent to behave well on its own and started shaping how it worked.
Then I realized: none of this is new. It's exactly what I do with people in my engineering teams. Every day. We just don't call it "configuration."
When a new engineer joins a team, we don't give them access to everything and hope for the best. We:
- Clarify ambiguity through onboarding docs.
- Define roles and responsibilities so two people don't step on each other.
- Set up review processes so no code ships without a second pair of eyes.
- Create communication ceremonies, standups, retros, architecture reviews, so context is shared across the team.
- Build an ops model that defines who owns what, who escalates to whom, and what happens when things break.
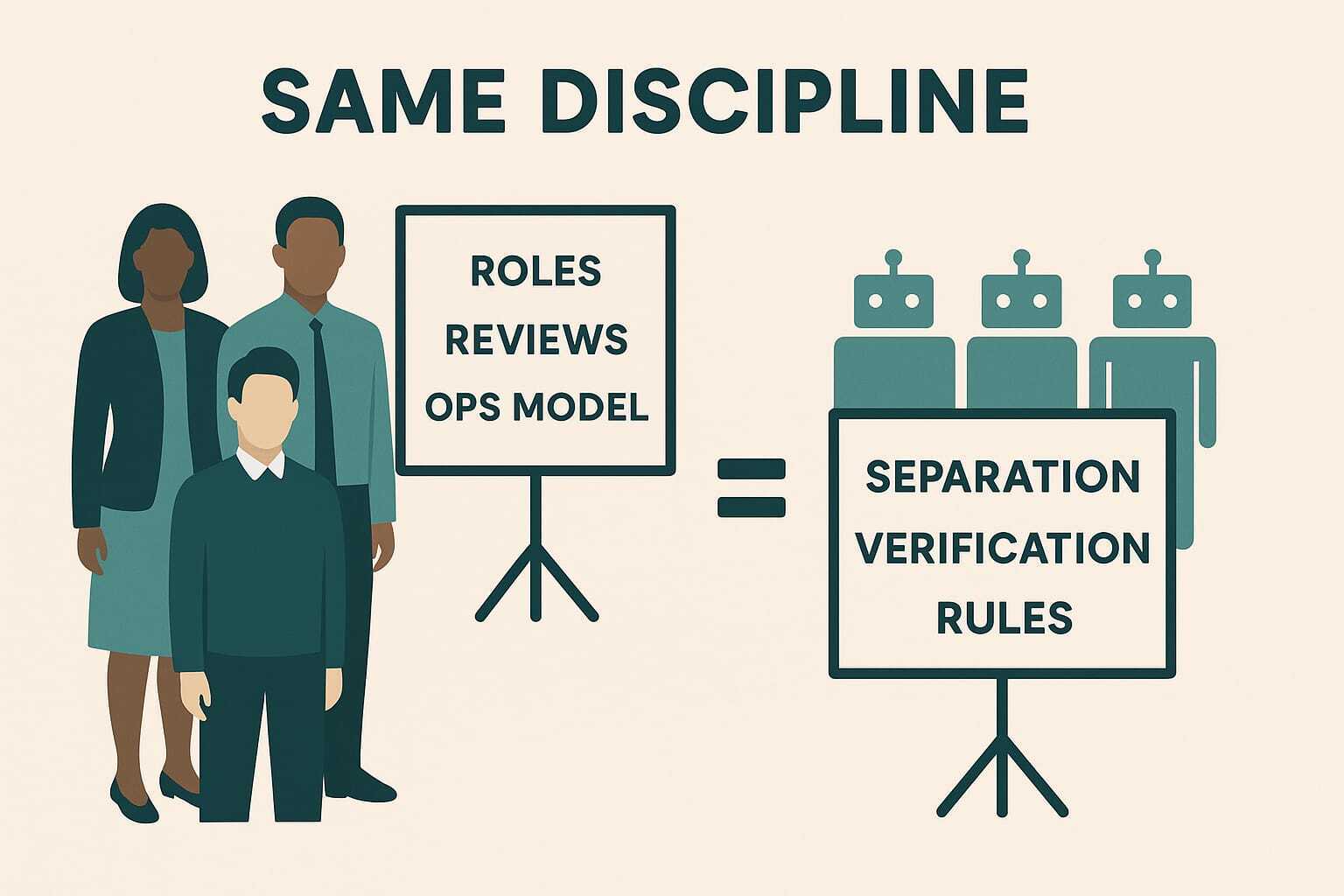
That's what agent configuration is. The same discipline, different medium.
The mapping is direct:
- Roles and responsibilities become agent separation: one agent writes code, another reviews it.
- Review processes become structural verification: a reviewer agent rejects work without evidence of testing.
- Communication ceremonies become context rules: the agent knows what it needs to check before acting.
- Skills become the single source of truth shared across all agents, the way a team wiki or engineering handbook works for people.
- Hooks act as hard rules, gatekeeping quality standards and feeding back learnings automatically.
- The ops model becomes agent orchestration rules in skills and hooks, or workflow configuration.
What works for people works for agents: clear scope, explicit boundaries, structural accountability. The difference is that agents don't forget the rules, don't get tired, and don't reinterpret them based on mood. But they can hallucinate and skip a rule entirely, different reason, very similar outcome. The discipline has to be structural, not hopeful. Once the configuration is right, it stays right. Until the agent finds a creative way to ignore it.
The principle is the same across every domain: autonomy without structure produces chaos. Structure without autonomy produces overhead. The breakthrough is finding the balance.
Once the configuration was right, everything changed. The hallucination rate dropped. I stopped auditing every action. The system became something I could trust for low-risk domains while maintaining oversight for high-stakes ones.
The breakthrough wasn't a better model. It was a better set of configurations and rules.
But rules alone weren't enough. And the system I ended up building, the separation of concerns, the layering of skills and tools, the concept of legible autonomy, that's a longer story. I'll cover the full architecture in the next article: Building the Configuration Layer, From Chaos to Legible Autonomy.
The Agentic-Native Company
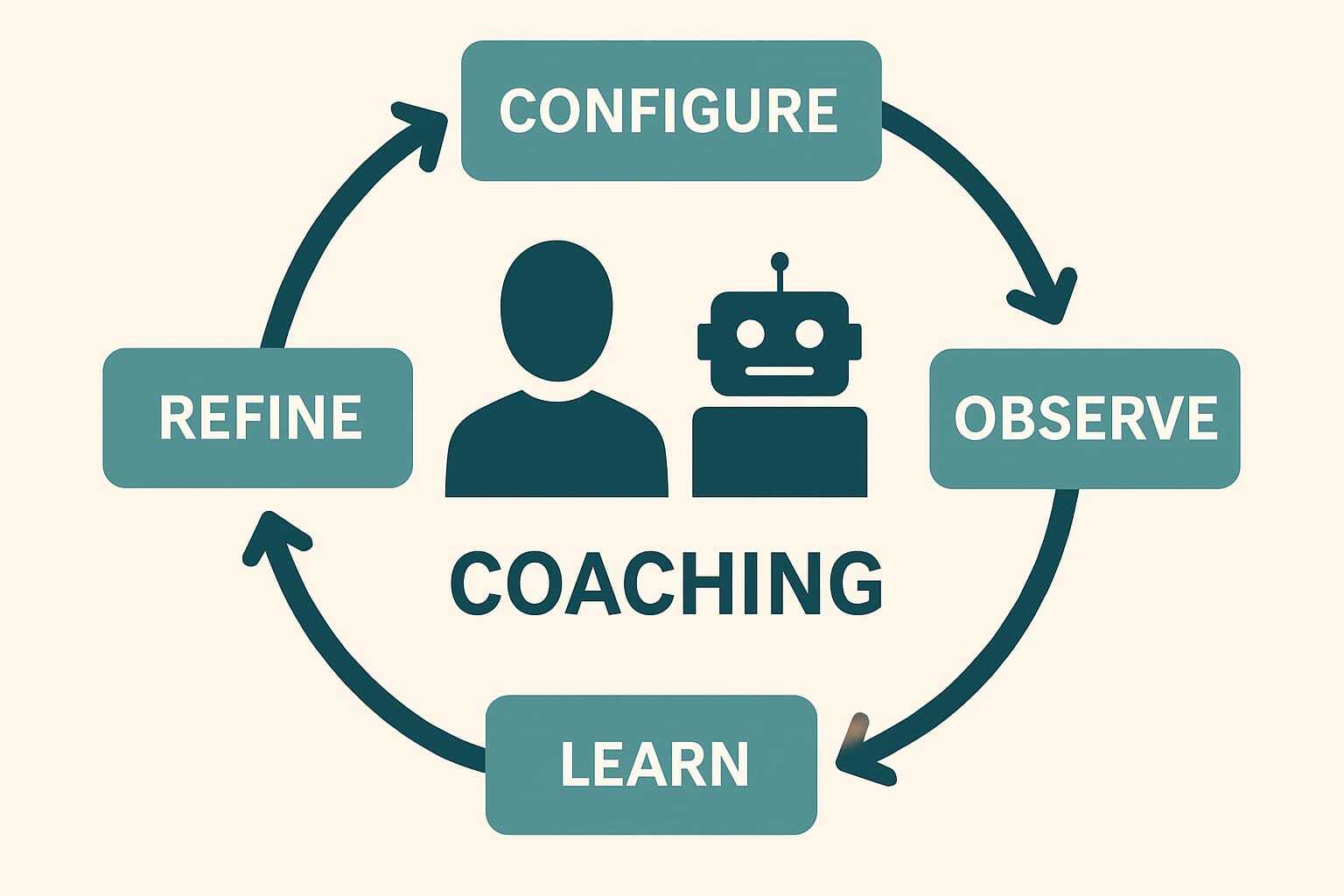
In the agentic-native company, agent configuration isn't a one-time setup task. It's continuous coaching. The same way you invest in your workforce through learning programs, mentoring, performance reviews, and career development, you invest in your agents through configuration tuning, memory refinement, and scope expansion.
The parallel is direct. HR runs talent management and learning programs because people don't arrive fully formed, and because the company's needs evolve over time. They grow through structured feedback, clearer context, and expanding responsibilities. Agents work the same way. Every configuration adjustment is a coaching session. Every memory update is institutional knowledge transfer. Every rule refinement is a performance review that sticks permanently.
Companies that treat agent setup as a project will fail the same way companies that treat employee onboarding as a one-week event fail. The ones that build a continuous coaching muscle, an equivalent to their talent management investment but for autonomous agents, will compound their advantage every week.
